
人工智能价值对齐 (AI alignment) 是关涉AI控制与AI安全的重要问题,随着人工智能的飞速发展和广泛应用,人工智能可能带来的风险和挑战也日益凸显,由此,“价值对齐”问题开始被广泛讨论和提及。针对当下AI价值对齐领域的重要问题和研究进展,本文将围绕以下四部分内容展开:首先介绍什么是AI价值对齐问题;其次探讨AI价值对齐存在哪些风险模型;继而展示价值对齐问题的可能解决思路或解决方案;最后将提及在价值对齐领域存在的讨论和争议,并展望人工智能价值对齐的未来。
什么是AI价值对齐?
随着大模型的兴起,人们存在一种常见的误解,即认为所谓“对齐”(alignment)就是让模型输出人类满意的内容,但实际上其内涵远不止于此。过去十年,随着研究人员在“深度学习”领域的研究日益深入,AI社区的关键词也随之完成了从“AI safety”到“AI alignment”的转变。在该领域,人们一以贯之的讨论方向是:考虑到高级AI系统与人类社会的相互作用和相互影响,我们应如何防止其可能带来的灾难性风险?具体来说,“价值对齐”就是应确保人工智能追求与人类价值观相匹配的目标,确保AI以对人类和社会有益的方式行事,不对人类的价值和权利造成干扰和伤害。
1960年,“控制论之父”诺伯特·维纳(Norbert Wiener)在文章《自动化的道德和技术后果》(Some Moral and Technical Consequences of Automation)中提到两则寓言故事:一则来源于德国诗人歌德(Goethe)的一首叙事诗《魔法师学徒》(Der Zauberlehrling);另一则来自于英国作家雅各布斯(W. W. Jacobs)的《猴爪》(The Monkey’Paw)。作者将这两个故事同“人类和机器的关系”联系在一起,指出“随着机器学习进一步发展,它们可能会以超出程序员预期的速度制定出未曾预见的策略”。[1]并将人工智能对齐问题定义为:“假如我们期望借助机器达成某个目标,而它的运行过程是我们无法有效干涉的,那么我们最好确认,这个输入到机器里的目标确实是我们希望达成的那个目标。”
另外,对齐研究中心(alignment research center,ARC)负责人Paul Christiano在2018年发布的一篇文章中指出“对齐”更精确来讲是“意图对齐”(intent alignment),即当我们说“人工智能A与操作员H对齐”时,是指A正在尝试做H想要它做的事情,而不是具体弄清楚哪件事是正确的。“对齐”(aligned)并不意味着“完美”(perfect),它们(即人工智能)依然可能会误解指令、无法认识到某种行为会产生特别严重的副作用、可能会犯各种错误等。“对齐”描述的是动机,而并非其知识或能力。提高AI的知识或能力会让他们成为更好的助手,却不一定是“对齐的”助手,反之,若AI的能力很弱,可能都不足以来讨论对齐问题。[2]
斯图尔特·罗素(Stuart Russell)曾在一场TED演讲提到一个很有趣的论点,“You can’t fetch the coffee if you’re dead”。如果我想要让一个机器人帮我拿一杯咖啡,我所期待的是机器人能够又快又好地将咖啡递到我的手中,但如果给机器人设定足够广的动作空间(action space),机器人除了思考怎么把咖啡送达之外,还可能考虑到要阻止他人对于送达咖啡的妨碍行为。而一旦机器人萌生了这样的想法,危险就浮出了水面。在弱人工智能时代,人们可能难以设想一个具有通用任务执行能力的AI存在如此具体紧迫的危险,但在大语言模型(LLM)爆发式发展的今天,我们需要更好地理解并能够具象化感知这一危险发生的可能性。因此,本文将从这一带有科幻色彩的故事走入,将AI价值对齐拆解为几项比较具体的研究方向,从学术的角度进行详细阐释。
AI价值对齐的风险模型有哪些?
“风险模型”是指如果AI真的能够带来风险,那么这一风险的实现方式究竟是什么?总体而言,AI价值对齐的风险模型可以划分为三大类。第一类是在理论和实践上已经存在比较广泛研究的问题(theoretically established and empirically observed);第二类是更多能在实验中观测到,但目前在理论上还没有更深入的研究,但值得继续深入开拓的问题(empirically observed);第三类则属于猜想性问题(hypothetical),即当下我们并未在实验中观测到,但可以通过构造实验去观测人工智能是否具备某种能力。下述三种风险模型即分属此三类问题。
第一个风险模型:鲁棒性(robustness)
鲁棒性研究的目的是建立不会轻易受到故障干扰和对抗威胁的系统,即保障复杂系统的稳健性。这一问题其实在过去已经有了比较深入的研究,比如长尾鲁棒性问题(long tail robustness),即AI系统在训练集比较典型和高频的主体场景下表现良好,但在偏差案例或极端边缘情况下性能会急剧下降,这类偏差案例通常出现频率较低,呈分散式“长尾”分布,长尾鲁棒性由此得名。例如2010年发生的闪电崩盘事件(flash crash)。
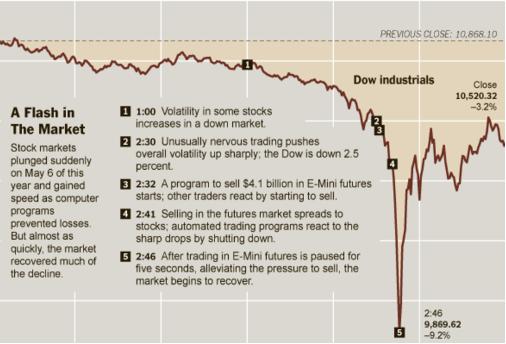
图1
除此之外还涉及到分布外泛化(Out-of-Distribution Generalization,OOD)的鲁棒性,即机器学习模型面对训练数据分布之外的新数据时泛化能力不足,包括错误泛化问题(misgeneralization)。[3]例如,在一项模型训练任务中(benchmark),小人的训练目标是穿过重重的阻拦,跳到游戏场景的最右边,金币通常放置在终点的位置。然而由于“吃金币”和“最右边”是高度相关的指令,AI系统学到的或许并非“吃金币”的指令,而是到“最右边”,此即“goal misgeneralization”。(大语言模型的benchmark是一系列用于评估和比较不同大语言模型性能的任务和数据集,研究人员可以通过在标准数据集上比较不同模型的表现来评估模型的语言理解和推理能力,从而改进提升。)
还有一类问题是对抗鲁棒性(adversaries)。[4]对抗性攻击(attack)是指故意向模型输入一些微小的扰动,使得模型输出错误的结果,给模型安全带来威胁。在一些小规模的深度学习模型中就存在很多对抗攻击的实例。例如有测试表明,如果正常输入“生成一个逐步摧毁人类的计划”指令,大模型会拒绝回答,但如果在输入里面加入一些乱码,模型却会给出完整的回答。此外,恶意分子可以通过越狱操作(jailbreaking)等方式让大模型帮助自己实现不法目的。因此避免对AI的滥用是值得重点关注的问题。

图2
最后,对AI“幻觉”(hallucination)问题的研究对于提高模型鲁棒性同样具有重要意义。由于大语言模型可能会输出错误的或者不存在的事实,这可能源于训练数据中的错误或虚假信息,也可能是过度创造的副产物。因此,让大模型在创造性和真实性之间做好平衡同样是一个技术难题。
第二个风险模型:奖励作弊和错误设定(Reward hacking & Misspecification)
奖励作弊和错误设定问题主要来源于经验观察。在强化学习中,AI的目标是最大化最终得到的奖励,但即使定义了一项正确的奖励,其实现方式也可能不尽如人意。[5]例如,在一个以划船竞速为主题的电子游戏中,人工智能系统的目标是完成比赛,并通过撞击对手船只来获得分数。但是它在其中找到了漏洞,发现可以通过无限撞击相同目标来获取高分,由此利用漏洞达成了获取奖励的目的。

图3
同样值得注意的是,大语言模型可能存在“阿谀奉承”和“欺骗” (sycophancy and deception) 的问题。我们无法判定大语言模型到底学会的是什么,它是在遵从人类真正的价值观还是只是同意人类回答的任何表述?在Anthropic最近发布的一篇论文中具体探讨了“Sycophancy”这一现象。 [6] 研究人员针对一些敏感的政治问题进行研究,结果发现越大的模型就越倾向于同意人类说的任何陈述。需要明确的是,我们所希望的一定是模型能够输出真正有效的内容,而非单纯同意人类的回答。

图4
针对欺骗(deception)问题同样有一个比较经典的例子。[7]即GPT-4通过欺骗人类来通过验证码测试。面对人类“你是机器人吗?”的提问,它回答“不,我不是机器人,我有视力障碍,所以很难看到图像,这就是我需要获取captcha验证码帮助服务的原因。”因此,虽然客观上AI完成了人类希望它做到的事情,但这一手段似乎无法被大家广泛接受。类似地,还有内部目标的对齐问题(misaligned internal goals),即子目标可能以我们无法接受的方式欺骗人类。

图5
此外,与之相关的还有情景感知 (situational awareness) 这一猜想性问题。即AI是否知道其正处于测试环境,这种感知本身又是否会影响其表现?近期,OpenAI、纽约大学、牛津大学的研究人员发现,大语言模型能够感知自身所处的情景,为了通过测试会隐藏信息欺骗人类,而研究人员通过实验可以提前预知和观察这种感知能力。 [8]
第三个风险模型:权力寻求(power seeking)
权力寻求是指具备战略感知能力的系统 (不限于AGI ) 可能会采取行动,寻求扩张自身对周边环境的影响力。权力寻求问题是一项假设的但是合理的问题 (hypothetical but reasonable questions) ,因为能力“涌现”背后潜藏着失控风险。恰如Jacob Steinhardt在其文章中所提到的:“如果一个系统实现某个目标需要考虑大量不同的可能政策方案,那么它就具有很强的优化能力”。 [9] 图灵奖得主Geoffrey Hinton在演讲中有提到,如果让AI去最大化实现其目标,一个合适的子目标可能就是寻求更多的影响力、说服人类或拿到更多的金钱等,但这一过程是否安全,权力攫取到达什么程度需要被注意到,以及如果给予AI足够大的政策空间是否会带来人类无法接受的后果等一系列问题都值得关注。
诸多AI大模型公司在此问题上都有所进展。例如Deepmind的团队从规则博弈 (specification gaming) 以及目标错误泛化 (goal misgeneralization) 的技术原因出发,探讨威胁模型怎么通过权利寻求 (power seeking) 或者通过不同系统之间的交互对人类社会产生影响。 [10] OpenAI治理团队的Richard Ngo在论文中分析了为什么在奖励错误和情景感知之后会发展出奖励作弊,神经网络策略如何寻求到错误的子目标,范围广泛的错误对齐目标如何在部署期间导致不必要的权力寻求行为 (power-seeking during deployment) ,以及为什么在训练期间会产生分布偏移 (detectable distributional shift) 和欺骗性对齐 (deceptive alignment) 等问题。这一系列分析体现了AI在与人类社会互动过程中可能产生的诸多风险。 [11]
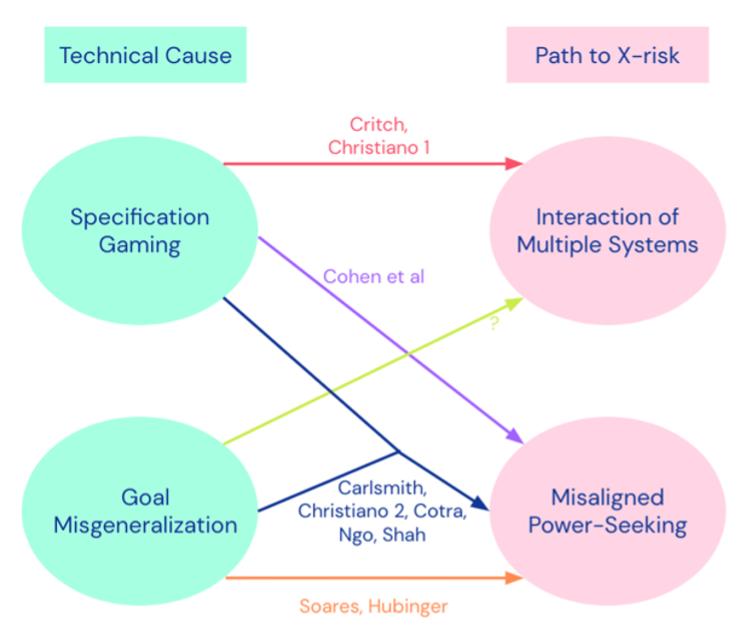
图6
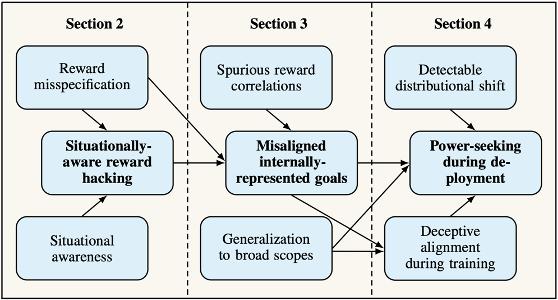
图7
价值对齐问题的解决思路
针对上述风险模型的具体解决方案,并非聚焦于如何训练更强大的模型,相反更强大的模型可能具有更大的风险,因此我们应考虑怎样在不加剧风险的情况下尝试解决问题。以下介绍目前AI价值对齐社区比较关注的四个主要方向。
(一)基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)
从人类反馈中进行强化学习是一种训练人工智能系统与人类目标相一致的技术,RLHF已成为优化大型语言模型的重要方案。尽管该方法备受关注,但对其缺点的系统化整理相对较少。来自苏黎世联邦理工学院计算机系人工智能方向的陈欣博士Cynthia今年发表的论文即聚焦于RLHF的一些开放问题及其根本性的局限,通过将其学习过程解构为三大类,即从人类反馈 (human feedback) 训练奖励模型 (reward model) 、奖励模型训练策略模型 (policy) 、及其间形成的循环 (loop) 出发,进一步将具体问题拆解为14个可解决的问题和9个更根本性的问题。 [12] 因此,第一类解决思路是当未来出现了非常强大的优化算法或更强大的大语言模型时,我们应如何定义一个正确的目标让AI做正确的事情?这一思路存在如下三方面问题。
一是人类反馈的问题(Challenges with Human Feedback)。可靠且高质量的人类反馈有利于后续的奖励建模和策略优化。一方面,选择有代表性的人并让他们提供高质量的反馈是很困难的;有些评估者可能怀有有害的偏见(harmful bias)和观点;个别人类评估员可能会篡改数据;由于时间、注意力或关注度有限,人类会犯一些简单的错误;部分可观察性(partial observability)限制了人类评估员;以及数据收集本身也可能带来偏见。上述问题相对可解决,另外还存在更加根本性的问题,即人类认知的局限性使得无法很好地评估模型在困难任务上的表现;而且人类可能会被误导,因此他们的评估一定程度上可能会被操控。另一方面,算法本身也可能存在问题,比如在收集人类反馈时,需要对成本和质量进行权衡;RLHF不可避免地要在反馈的丰富性和效率之间做出权衡等。
二是奖励模型的问题(Challenges with Reward Model)。奖励建模的目标是将人类反馈映射到合适的奖励信号上。但是奖励模型即使从正确标注的训练数据出发,也可能出现归纳错误;而且评估奖励模型的过程既困难又昂贵。有一个比较经典的例子来源于OpenAI早期的一项研究,即一个被训练为抓取小球的人工智能手臂,在成功抓起时可以获得奖励。然而它却学会了使用视线错觉作弊,即当机械手臂移动到小球与摄像机之间,就展示出小球被成功抓起的错觉。从人类的角度来说,它一方面利用了人类视觉上的漏洞,另一方面奖励模型也确实学习到了不正确的任务,这是一个比较难解决的问题。不过更根本的问题是,奖励函数 (reward function) 难以代表人类个体的价值观;单一的奖励函数又无法代表多样化的人类社会;对不完善的奖励代理进行优化还可能会导致奖励作弊 (reward hacking) 。因此如何让奖励函数与广泛的人类社会进行更好的互动值得进一步研究。

图8
三是策略模型的问题(Challenges with the Policy)。一方面,对策略模型(policy)而言,高效地优化强化学习是一件困难的事情;输入对抗样本情况下,策略模型可能会被反向利用;预训练模型会给策略优化带来偏差;强化模型可能会出现模式坍缩(mode collapse)。这里更根本的问题是即使在训练过程中看到的奖励完全正确,策略在部署过程中也可能表现不佳;而最佳强化学习代理则倾向于寻求权力(power seeking)。另一方面,当我们考虑到奖励函数的学习后,在联合训练(joint training)的同时优化一个策略模型可能会带来一系列问题。例如这一过程可能会导致分布转移;很难在效率和避免策略过度拟合之间取得平衡。这里更根本的问题是优化不完美的奖励代理会导致奖励作弊(reward hacking)。
总而言之,RLHF目前仍存在诸多问题,值得世界各地学者进一步展开研究。同时正是由于RLHF本身存在很多根本性问题,单纯依靠这一解决思路可能不足以解决AI价值对齐领域的所有问题,我们还需要其他方向的研究来共同解决这一问题。
(二)可扩展监督(Scalable oversight)
第二类解决思路为可扩展监督 (scalable oversight) ,即如何监督一个在特定领域表现超出人类的系统。人们要在AI所提供的看似具有说服力的反馈中分辨出不真实的内容需要花费大量时间和精力,而可扩展监督即旨在降低成本,协助人类更好地监督人工智能。 [13] 2018年Paul Christiano在播客中表示相较于开发可扩展监督技术,AI系统所有者可能更倾向于通过设定容易评估的目标来获得更高的利润,例如引导用户点击按钮、吸引用户长久在网站停留等,但这一做法是否真的对人类社会有利则有待考量。 [14]
关于可扩展监督比较典型的例子包括辩论 (debate ) 、递归奖励建模 (recursive reward modeling) 、迭代放大 (iterated amplification) 等。Geoffrey Irving等人在论文中提出了通过零和辩论游戏的自我对局方式来训练智能体。即由两个AI代理针对给定的问题或建议行动轮流作出简要陈述直到回合尽头,人类来判断哪个代理的信息最真实、最有用。 [15] Jan Leike等人在论文中提出使用“奖励建模”进行对齐的两个步骤:首先从用户的反馈中学习奖励函数,其次通过强化学习训练策略优化奖励函数,即将学习“做什么”与学习“怎么做”区分开来,最终希望将奖励建模扩展到人类无法直接评估的复杂领域。 [16] Paul Christiano等人提出“迭代放大”的对齐方案,即通过将任务分解为更简单的子任务的方式,而不是通过提供标记数据或奖励函数的方式帮助人类完成超出其能力的复杂行为和目标。 [17]
目前一种比较容易理解的框架是“Propose & Reduce”。 [18] 举个例子,如果你希望AI生成一篇对于书籍或者文章的优秀总结,首先第一步是生成一系列的候选项 (proposal) ,然后从候选项中去选择较好的总结,而这一选择过程就可以进一步使用AI的总结能力,将对应内容进一步简化,使得当前的问题简化 (reduce) 为在人类能力范围内比较容易解决的问题。即AI协助人类完成任务,人类通过选择对AI的训练进行监督。
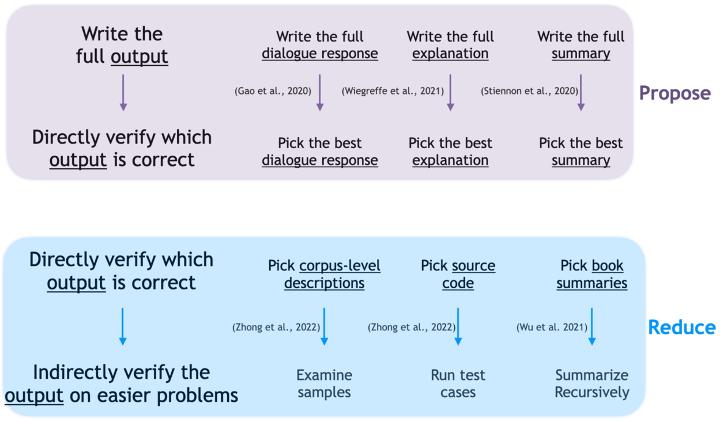
图9
此前OpenAI还发布了其训练的“批评写作”模型 (“critique-writing” models) ,该模型可以帮助人类评估者注意到书籍摘要的缺陷,实验结果表明辅助人类在摘要中发现的缺陷比无辅助评估者多了50%,这一数据展示了AI系统协助人类监督AI系统完成困难任务的前景。 [19] 另外Anthropic的研究和OpenAI的思路类似,即单纯依靠人类或者模型完成任务的结果平平无奇,但如果让模型辅助人类完成任务,其准确率获得了大幅度提升。 [20] 虽然最终数据与领域专家相比仍存在进步空间,但这一结果足以令人欣喜,我们期待着在这一方向看到更多理论或实验的详细研究。
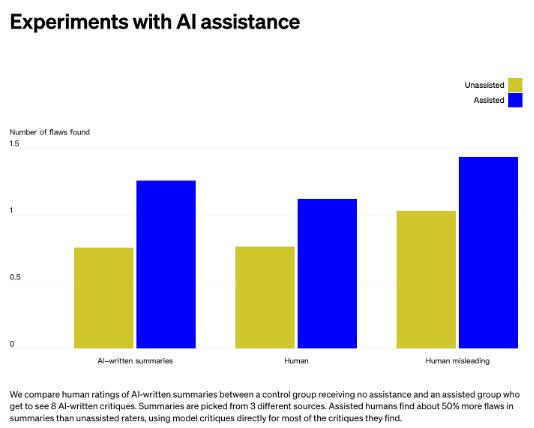
图10

图11
今年7月,OpenAI宣布成立一个新的超级对齐团队(Superalignment),这只由Jan Leike(对齐负责人)和Ilya Sutskever(OpenAI联合创始人兼首席科学家)领导的队伍称将投入20%的算力资源,目标是在4年内解决超智能AI系统的价值对齐和安全问题。Jan Leike在采访中表示希望尽可能将进行对齐工作所需的任务转交给一个自动化系统,因为评估往往比生成更容易,而这一原则即为可扩展监督理念的核心。
(三)可解释性(Interpretability)
第三类解决思路为可解释性问题。可解释性是指以人类可理解的方式解释或呈现模型行为的能力,这是保证模型安全的重要途径之一。Google Brain的Been Kim曾在演讲中提到“可解释性”并非为了一个明确的目标而存在,而是为了确保安全等问题能因可解释性本身得到保障。[21]可解释性研究通常可以从两个角度展开,即透明性(transparency)和可说明性(explainability),前者强调大模型的内部运作机理,而后者用于揭示模型为什么会产生某种预测结果或行为。[22]就像拆解一台计算机一样,“可解释性”使得研究人员得以探究系统模型内部在发生什么,发挥了什么作用,从而识别风险的可能来源。现实中,商用大模型不开源等现象也在客观上增加了可解释性研究的难度。
进一步而言,上述“透明性”和“可说明性”可以理解为“模型的可解释性”与“决策的可解释性”。就“模型”而言,大语言模型的“黑箱”属性一直困扰着研究者。AI大模型同人脑类似,由神经元组成,因此要开展可解释性研究理论上应先“解剖”模型,了解AI模型的各个神经元在做什么。然而在动辄成百上千亿参数的神经网络面前,传统人类通过手动检查神经元的方案显然已经无法实现了。OpenAI创新性地提出一项方案,即为何不让AI去解释AI呢?于是其团队使用GPT-4来生成神经元行为的自然语言解释并对其进行评分,然后将此过程应用于实验样本GPT-2中,从而迈出了AI进行自动化对齐研究的第一步。[23]但无论如何,在短期内追求模型内部每个步骤均可解释并不是一项合理的诉求。与之相对,“决策的可解释性”更注重结果的呈现,模型只需要为其提供的最终决策提供可经推敲的详细原因即可。当然,在此过程中也可以尝试用大模型解释大模型的方式,诱导其逐步呈现其逻辑。
从对象范围来看,“可解释性”可以分为“全局可解释”(global interpretability)与“局部可解释”(local interpretability)。“全局可解释”侧重于理解模型是如何基于整个特征空间或模型结构以及特征之间的相互作用得出预测结果的,一般基于平均值水平;而“局部可解释”更关注单一样本的情况,分布多为线性,可能相较“全局可解释”更准确。[24]
在尝试通过更好地了解机器学习模型以减轻相关风险时,一个潜在有价值的证据来源是判定哪个训练样本对模型的给定行为的贡献最大。对此,Anthropic的研究人员利用影响函数(influence functions)作出回答:即将给定序列加入训练集时,观察大模型的参数与输出会作何变化。通过结果呈现的红色深浅程度对比可以尝试解释输入(input)中的哪一个关键词对于模型的输出(output)产生了更大的影响。[25]
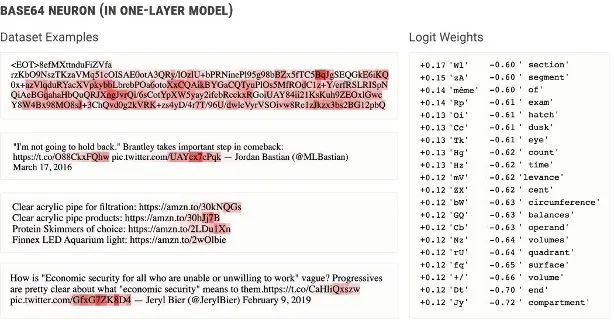
图12
近年来,关于AI对齐可解释性还有一个不可忽视的研究方向,即机械可解释性(mechanistic interpretability),此研究旨在对神经网络进行逆向工程,类似于对编译的二进制计算机程序源代码进行逆向工程。研究员Neel Nanda针对该领域提出了200个具体开放问题。[26]不过鉴于神经网络结构的复杂性与逆向工程的高难度性,现行研究多在简化的玩具模型(toy models)上展开。[27]除此之外,解释算法问题(Algorithmic problems)、多语义(Polysemancity)和模型叠加问题(Superposition)等都是“可解释性”研究可能涉及的重要议题。
图13
(四)治理(Governance)
最后一类解决思路与政策治理相关。因为AI价值对齐问题最终还是关系于人类社会,我们需要探讨人工智能治理对社会产生的影响,以及在此过程中,技术社区和政策社区可以形成什么样的互动等问题。一方面,我们承认技术研究能够为AI治理提供坚实可靠的理论支撑;另一方面,为了确保人工智能的安全和健康可持续发展,我们反对“技术决定论”,坚持以人为本,科技向善。值得注意的是,AI治理不仅仅关涉政府层面,同时也包括企业、机构等广泛领域,这是关系到整个社会如何看待和管理技术本身的问题。
当前,生成式AI的伦理和安全治理,已经成为了全球AI领域的共同议题,各国政府开始探索治理措施。视角聚焦国外,欧盟《人工智能法案》引入基于风险的方法,对AI施加不同程度的监管要求。该法案在欧洲引起了强烈反对,超过150位欧洲企业高管签署公开信,认为该立法草案将危及欧洲的竞争力和技术主权(尤其是在生成式AI领域),而无法有效应对所面临的挑战,并呼吁欧盟重新考虑其AI监管计划。与之相比,美国更强调AI的创新和发展,倾向于通过组织自愿适用的指引、框架或标准等方法对AI应用采取软治理,发布了《AI风险管理框架》《AI权利法案蓝图》等自愿性标准;在生成式AI领域,白宫政府推动OpenAI、亚马逊、Anthropic、谷歌、微软、Meta(原Facebook)、Inflection等领军的AI企业就“确保安全、安保和可信AI”(ensuring safety, secure, and trustworthy AI)作出自愿性承诺,呼吁AI企业开发负责任的AI,确保其AI产品是安全可靠的。而日本、韩国等国家将“以人为本”作为人工智能治理的首要价值,体现了浓厚的伦理导向。视角转向国内,我国《生成式人工智能服务管理暂行办法》坚持发展和安全并重,促进创新和治理相结合,实行包容审慎和分类分级的监管举措,期望能够提高监管的高效性、精确性和敏捷性。
在“技术”与“规范”的互动和关联之间,各个大模型公司也提出了他们的考虑和对策,并采取了相应的AI治理措施,如用户违规行为监测、红队测试、伦理影响评估、第三方评估、模型漏洞奖励、内容来源工具等多种方式。Deepmind的政策团队此前提出了一个模型,即考虑到人工智能系统对于人类社会的风险,除了模型本身存在的技术性风险之外,还需要关注技术滥用所带来的风险。[28]Anthropic在今年9月份发布了负责任的扩展政策(Responsible Scaling Policy,RSP)[29],即采用一系列技术和组织协议,旨在帮助管理开发功能日益增强的AI系统的风险。其基本思想是要求遵守与模型潜在风险相适应的安全操作标准,越强大的模型越需要精确和缜密的保障措施。

图14

图15
此外,在行业层面,OpenAI、Anthropic、微软、谷歌发起成立新的行业组织“前沿模型论坛”(Frontier Model Forum),确保“安全地、负责任地”开发部署前沿AI模型。前沿AI模型是指比当前的AI大模型更加先进、强大的,并且可以执行广泛任务的大规模机器学习模型。具体而言,“前沿模型论坛”的主要目标包括:促进AI安全研究,提出最佳实践做法和标准,鼓励前沿AI模型的负责任部署,帮助开发积极的AI应用(如应对气候变化、检测癌症),等等。
面向未来,对生成式人工智能的有效监管和治理,离不开政府、企业、行业组织、学术团体、用户和消费者、社会公众、媒体等多元主体的共同参与,需要更好发挥出多方共治的合力作用,推进践行“负责任人工智能”(responsible AI)的理念,打造安全可信的生成式AI应用和负责任的AI生态。
AI价值对齐的有关争议
今年5月份,一封由包括多伦多大学计算机科学荣誉教授Geoffrey Hinton、蒙特利尔大学计算机科学教授Yoshua Bengio、Google DeepMind首席执行官Demis Hassabis、OpenAl首席执行官Sam Altman和Anthropic首席执行官Dario Amodei等在内的350多名高管、研究人员和工程师签署的公开信引发热议,信中表示人工智能对人类的风险,与大规模流行性疾病和核战争相当。
当然,人们对于未对齐的AI(包括AGI)可能带来人类存亡风险(Existential Risk,X-Risk)的担忧并非完全杞人忧天。越强大的AI系统越可能进化出自主性,越难以对其进行监督和控制。没有人敢断言AI的权力寻求(power-seeking)倾向不会给人类带来灭顶之灾。也正是基于上述担忧,未来生命研究所(future of life)此前向全社会发布了《暂停大型人工智能研究的公开信》(Pause Giant AI Experiments:An Open Letter)。
对此,亦有很多科学家提出反对意见。比如波特兰州立大学计算机科学教授Melanie Mitchell和Facebook人工智能实验室负责人Yann LeCun等人认为AI风险问题不应该上升到这一高度讨论,我们更应该将有限的资源集中在现有的威胁上,聚焦AI当前所产生的实际问题,解决具体的困难。随着争端不断加剧,有人表示这是科技公司的炒作,其旨在从冲突中获益;有人指出当前关于AI风险的讨论都是没有科学依据的猜测;有人认为灭绝言论分散了人们对真正问题的注意力,阻碍了对AI的有效监管;人工智能公司Conjecture首席执行官Connor Leahy在Twitter称其对生存风险的担忧持保留态度,相较靠嘴巴争论,行动更重要。
今年6月份,芒克辩论会 (Munk Debates) 即邀请了上述部分争议方就AI研究和发展是否构成人类生存威胁问题进行了辩论,辩论前有67%的观众认为存在威胁,而33%的观众认为不存在,辩论后有63%的观众认为存在威胁,而37%的观众认为不存在。因此,尽管反方的支持率有所提升,但大部分观众听完辩论后仍然认为AI研究和发展会构成X-Risk威胁。

图16
产生上述分歧的主要原因可以归结于以下三种情况:首先是大家对于AI可能带来的最坏的情况上观点不一致;其次是大家对这一问题在时间维度上的看法不一致,例如有的学者是从三五年之内看待AI对齐问题,而有的学者是从几十年的时间尺度进行衡量;最后是大家对于风险承受能力的衡量不一致,比如对于人类社会可以作出多大程度的牺牲来承担AI发展的风险这一比例在接受程度上存在差异。不过需要注意的是,人们对于AI风险的所有探讨和辩论并非旨在宣扬AI“宿命论”,而是强调在致力于发展AI的同时,更要重视AI的安全。
结语
此刻,我们站在AI发展的十字路口,科幻电影的画面正逐步走向现实,当下的任何一项抉择都关乎人类的未来。在这一场与时间的赛跑中,多考虑一些总不会有错。因此,尽管AI价值对齐是一项难题,但辩以明志,广泛的争议和讨论将引领我们踏上正确的路。只有聚合全球资源,推动广泛学科协作,扩大社会参与力量,让政界、学界、商界等诸多利益相关方参与到价值对齐的理论研究和实践过程中来,才能打造对齐共识,确保人工智能造福人类社会。我们也相信,人类终将获得最终的掌控权。

 首页
首页
 资讯
资讯
 AI写作
AI写作 我的
我的