

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
刚刚过去的春节,DeepSeek-R1 推理大模型引爆了国内外 AI 社区,并火出了圈。最近,各个行业又掀起了接入 DeepSeek 的狂潮,大家唯恐落后于人。
北大 AI 对齐团队对包括 DeepSeek-R1、Kimi-K1.5在内的一些强推理模型进行了 2 万字的技术解读,也是此前 o1 解读(北大对齐团队独家解读:OpenAI o1开启「后训练」时代强化学习新范式)的续作。

视频链接:
https://mp.weixin.qq.com/s/W7X5_9uVTstInev3-UjExg
以下为完整的文字解读稿(以第一人称我们陈述):

下图是我们这次讨论的一个目录,涵盖了包括 DeepSeek-R1、Kimi K1.5 的具体的技术分析和讲解。同时也包括对其背后的社会和经济效益以及一些 insights 和 takeaways 的分析。
具体地来说,我们会进行相应的技术细节的讨论:比如说基于 STaR 的方法和基于强化学习的方法进行强推理模型复现的区分和产生的效果的不同。这里面就包括了 DeepSeek-R1、Kimi K1.5 和 o 系列的模型。我们也会分析蒸馏和强化学习驱动下不同的强推理路径复现的区别,同时也会探讨 PRM 和 MCTS,也就是蒙特卡洛树搜索在整个强推理模型构建过程中的作用。其次我们也会探讨一些从文本模态到多模态的实践。最后我们会对未来的方向进行一个分析和探讨,包括模态穿透、探索合成数据以及强推理下的安全。我们也会补充拓展 DeepSeek-v3 的解读。

DeepSeek-R1 开创 RL 加持下强推理慢思考范式新边界
近期后训练阶段开始成为语言模型中在完整训练过程中非常关键的一环,包括提升推理能力和社会价值对齐方面起到了非常重要的作用。自从 OpenAI o1 开启后训练强化学习新范式后,社区研究 Inference Time Scaling 通过增强 CoT 的长度提升推理能力的热情也是在逐渐增高。其中一个关键的问题就是如何通过有效的测试阶段的时间的扩展来提升它的推理能力。
近期 DeepSeek R1 的开源,也是再次让我们看到了强化学习的潜力。得益于纯大规模强化学习 DeepSeek-R1 Zero 和 DeepSeek-R1 的出现其实大大提升了推理能力和长文本的思考能力,其中 R1 Zero 是完全从基础模型开始构建,完全依赖强化学习,而不使用人类专家标注的监督微调。在训练过程中随着训练步骤的增加,模型也是逐渐展现出长文本推理以及长链修复的能力。随着推理路径的逐步增长,模型来表现出自我反思的能力,能够发现并修复之前的错误。
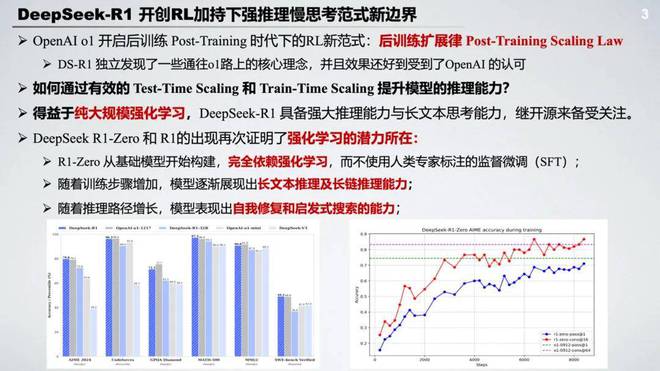
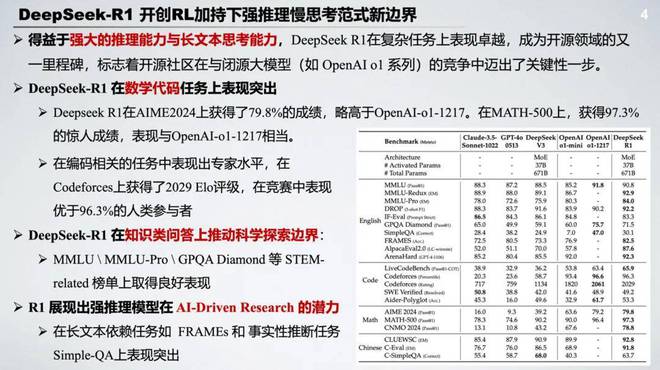
得益于强大的推理能力和长文本思考能力,DeepSeek R1 在开源以来就备受关注,其中它在著名的数学代码任务榜单上也是获得了非常突出的表现。比如在 AIME2024 上取得了 79.8% 的成绩,也是超过了 OpenAI o1。其中也在编码的任务上表现出了专家水平。与此同时,DeepSeek R1 在知识类问答的任务上推动了科学探索的边界,在无论 MMLU 还是 GPQA 等一些基于科学问答和理工类的榜单上都是取得了比较好的表现。更令人惊艳的是 R1 在一些长文本依赖的任务上比如 FRAMEs 和一些事实性推断任务上也是表现突出,其实也展现出来了强推理模型在 AI 驱动的一些 research 的潜力。
那么我们首先回顾一下预训练阶段的扩展律。其实也就是在预训练模型上,计算量数据和参数量成一个类似于正比的关系,也就是算力等于 6 倍的参数量乘上数据量。因此在大模型时代发展的初期,囤卡提升预训练的算力和模型参数变成了主要目标。

随着 OpenAI o1 的发布,也证明了在强化学习加持下后训练时代一个新的扩展律:随着模型在后训练阶段的训练时计算量和测试时计算量的提升,模型的性能特别是数学代码能力也会随之提升。那么在后训练扩展律下语言模型的训练时计算量多了一个新的变量,也就是在探索时语言模型推理产生的计算量。

为什么我们需要后训练扩展律?其实早在 2022 年就有启发的认知,主要是出于两个原因:第一个是随着模型尺寸的逐渐增大,预训练阶段参数的扩展带来的边际收益开始逐步递减,如果想要深度提升模型的推理能力和长程问题的能力,基于强化学习的后训练将会成为下一个突破点;第二个也就是自回归模型在传统的像数学推理问题上很难进步,其中的关键一点就是没有办法进行回答的自主修正,那如果仅是依靠生成的方法和扩大参数的规模在数学和推理任务上带来的收益不会很大。所以我们迫切地需要额外的 Scaling Law 也是额外的扩展律。

DeepSeek-R1 Zero 及 R1 技术剖析
业界其实近期有很多复现 o1 的操作,例如基于蒸馏或者强化学习的方法或者是从 MCTS 也就是蒙特卡洛树搜索和奖励模型的设计角度出发。通过搜索的方式显式的去帮助语言模型进行推理阶段计算量的提升,也有很多不错的尝试。但是大多数都是在特定任务上,例如数学或者代码的提升。
DeepSeek R1 Zero 的发布也是让我们看到了强化学习的潜力,特别是它跳过了经典后训练阶段中的监督微调,直接运用大规模强化学习就实现了推理能力的大幅提升,在数学代码等问题上显著飞跃。并且在强化学习训练过程中自然涌现长文本推理能力,这其中的关键操作核心在于一个是基于规则的奖励 Rule-based Reward 和以推理为中心的大规模强化学习。接下来我们也进行逐步的拆解。
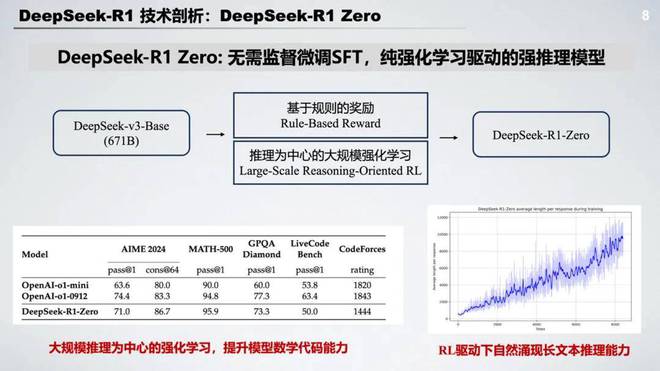
在 DeepSeek R1 Zero 的奖励建模中采用了基于规则的奖励,也就是基于一定的规则可以直接利用程序进行判断正误的奖励信号。
具体来说 DeepSeek R1 Zero 设计了两种奖励:一种是准确率奖励,即对于推理任务是否根据最后答案的正确率直接来判断这个任务是否成功完成;第二种是格式奖励也就是显式的去规劝模型的输出过程中必须包含思考的过程,利用一个 thinking token 将思考的过程圈起来。需要注意的是这部分奖励建模并没有采用先前我们经常讨论的比如说过程奖励模型 PRM 甚至没有采用奖励模型。这里边的主要考量是基于神经网络的奖励模型都有可能遭受奖励攻陷的问题,一旦发生奖励攻陷模型就可能陷入局部最优解,而重新训练奖励模型需要大量的计算资源可能会复杂化整个流程。
而第二个在强化学习的训练模板选择上,DeepSeek R1 Zero 采用了最简单的思考过程,而没有去在 system prompt 中加入过多的去诱导模型产生特定的思考范式,比如说去产生反思等范式。这一期望是可以希望能够直接观察到在 RL 过程中最本质的表现。

DeepSeek R1 Zero 更为关键的是以推理为中心的大规模强化学习。具体来说在传统的 RLHF 算法上 DeepSeek 进行了一些算法的细节优化,采用了像组相对策略优化也是 GRPO,这部分我们也会后续讲解技术细节。同时它只瞄准了推理方面的专项任务。通过大规模的强化学习模型已经呈现出了自我迭代提升的趋势,也就是随着训练步数的增加模型的思考长度会逐渐增长,这也对应着模型在测试阶段的计算量的增长,也就是推理时长的提升。
与此同时模型也在中途训练过程中涌现了 'Aha' moment,学会用 wait 等停顿词,自然的去增加更多的推理时间,并且反思和评价先前的步骤并主动去探索其他的方法路径。





 首页
首页
 资讯
资讯
 AI写作
AI写作 我的
我的